PLX-OCR v1.0
Next-generation Optical Character Recognition powered by advanced AI. PLX-OCR supports agnostic multilingual input and delivers industry-leading accuracy in Arabic text extraction. It's trained to identify sensitive data, parse complex tables into JSON, and extract text from any document with unmatched speed—making it a powerful solution across a wide range of applications.
Why Choose PLX-OCR?
Advanced AI technology meets enterprise-grade reliability
Lightning Fast
Process documents in seconds with our optimized AI pipeline
Pixel Perfect
Industry-leading accuracy even with poor quality images
Multi-Language
Support for 40+ languages and scripts worldwide
Enterprise Security
End-to-end encryption with advanced privacy measures
Smart Processing
AI-powered layout detection and text structure preservation
Developer Friendly
RESTful APIs with comprehensive SDKs and documentation
See PLX-OCR in Action
Real examples showcasing our OCR capabilities across different document types


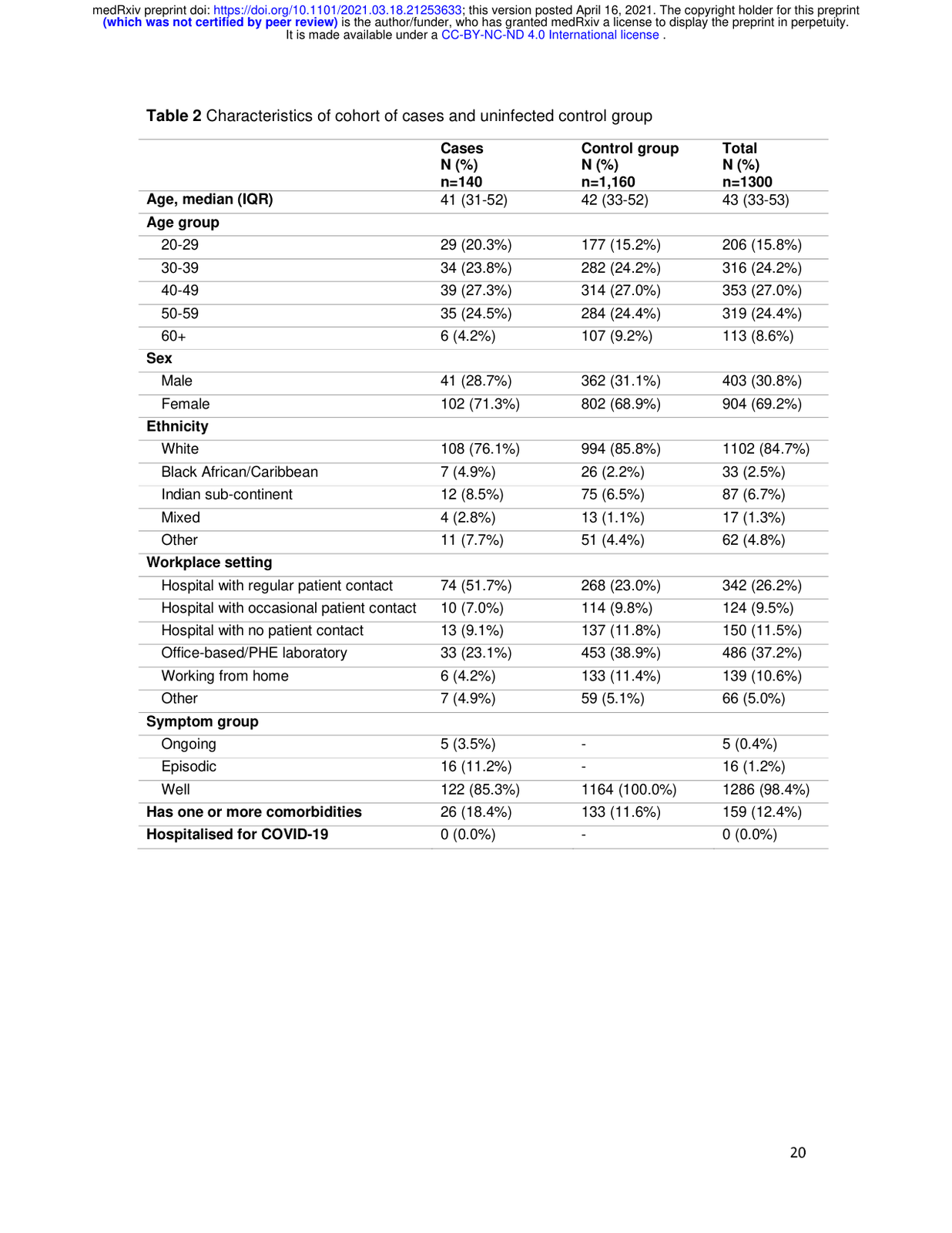
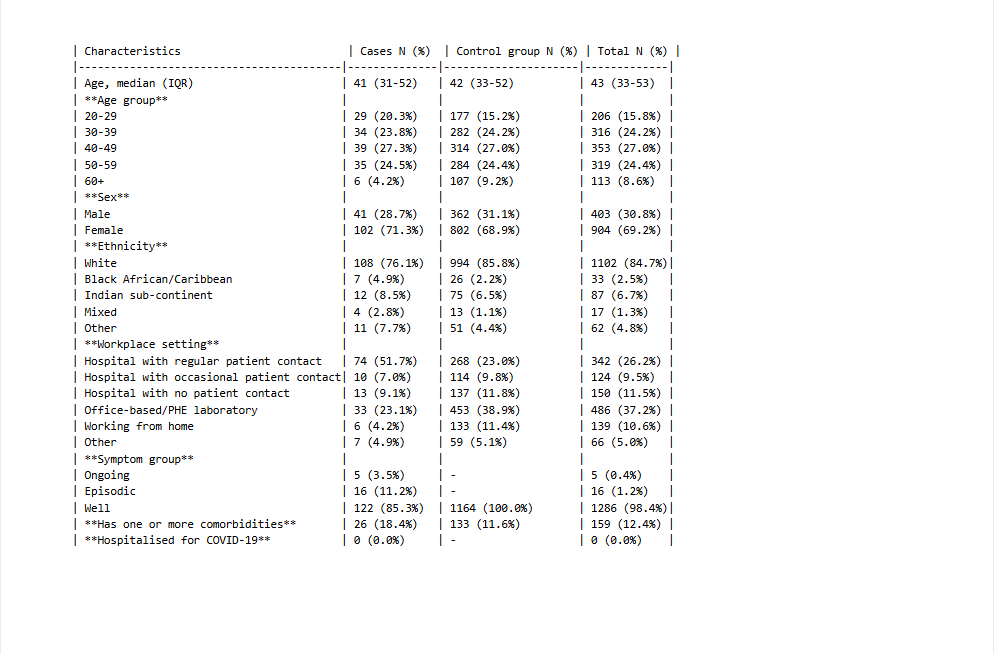
Example 1: Tables and Formulas
Even with complex tables, technical notation, and dense academic language, our advanced OCR captures structure, preserves mathematical formatting, understands scientific context—and even parses tables directly into JSON-ready data.
✓ Challenges Overcome:
- Complex Scientific Notation and Mathematical Symbols.
- Structured Tables with Mixed Numeric and Symbolic Content.
- Degraded Print Quality and Dense Text Layout.
⚡ Processing Stats:
- Processing time: 3 seconds
- Accuracy: 98%


Example 2: Arabic handwriting
This challenging handwritten medical manuscript features multiple ink colors, diagonal marginalia, and inconsistent scripts and numeral systems, complicating automated recognition. Our advanced vision-language OCR accurately decodes even difficult handwriting while preserving medical terminology and context.
✓ Challenges Overcome:
- Multi-Color Text: The document uses both black and red ink.
- Marginal Notes (Marginalia).
- Inconsistent Numeral Systems.
⚡ Processing Stats:
- Processing time: 2.2 seconds
- Accuracy: 95.8%
- Words detected: 130








Simple, Transparent Pricing
Choose the plan that fits your needs. No hidden fees, cancel anytime.
Starter
- 5,000 pages/month
- Basic API access
- Email support
- Standard processing speed
- Priority processing
- Custom integrations
Professional
- 25,000 pages/month
- Full API access
- Priority support
- High-speed processing
- Batch processing
- Webhook notifications
Enterprise
- Unlimited pages
- White-label API
- 24/7 phone support
- Dedicated infrastructure
- Custom integrations
- SLA guarantees
All plans include SSL encryption, GDPR compliance, and 99.9% uptime SLA
Frequently Asked Questions
Everything you need to know about PLX-OCR
PLX-OCR is an integrated solution designed to handle a wide variety of file formats across multiple document types.
Supported formats include:
Image formats:
PNG, JPG, JPEG, BMP, TIFF, WebP, PNMPDF formats:
Single and multi-page PDF filesOffice formats:
DOC, DOCX, XLS, XLSX, PPT, PPTXEmail formats:
EML, MSG, MBOXOthers:
TXT, RTF, HTML, XML
We support documents up to 50 MB in size and ensure high‑accuracy text extraction across all supported types.
Our accuracy rates vary by document type: 99.8% for printed text, 97% for handwritten text, and 95% for poor‑quality scans. We continuously improve our models with new training data.
Absolutely. We use end-to-end encryption and never store your documents after processing. Your data is processed in secure, isolated environments.
Yes! We provide RESTful APIs, SDKs for popular languages, webhook notifications, and pre-built integrations for platforms like Zapier, Make, and Microsoft Power Automate.
PLX-OCR v1.0, including both the API and SDK, will be available to all users starting January 1, 2026.
Early access will be granted to select exclusive users ahead of the public release.